Converter PDF em DOCX com Python: scripts em lote e ferramentas confiáveis

Resumo
Este guia mostra como converter PDF em DOCX com Python usando bibliotecas como pdf2docx e PyMuPDF, além de ferramentas de desktop. Você também verá exemplos de processamento em lote, OCR e monitoramento automático de pastas para criar fluxos estáveis. Continue lendo para evitar dores de cabeça e ganhar tempo no dia a dia.


| Tipo de problema | Causa típica | Pré-verificação / diagnóstico |
|---|---|---|
PDFs digitalizados | Sem texto selecionável | Abra o PDF e tente destacar o texto; se nada for destacado, é necessário OCR |
Tabelas/layouts complexos | pdf2docx não possui um mecanismo de layout | Converta primeiro uma página e verifique se há colunas deslocadas |
Fontes incorporadas / texto ilegível | Subconjunto de fontes ou codificação não padrão | Procure no DOCX por □ ou símbolos aleatórios |
Falhas em grandes lotes | Memória insuficiente ou conflitos de dependência | Teste com 5–10 arquivos; monitore o uso de RAM |

| Abordagem | Melhor para | Limitação principal |
|---|---|---|
pdf2docx | Conversões rápidas de PDFs digitais | Fraco com layouts complexos; sem OCR |
PyMuPDF + python-docx | Controle total e lógica de extração personalizada | Exige muito código para reconstrução de layout |
pdfplumber | PDFs centrados em tabelas | Sem saída em DOCX; apenas extração de texto |
Pandoc | Pipelines scriptáveis; fluxos multi-formato | A qualidade PDF→DOCX depende do LaTeX/leitores de PDF |
LibreOffice CLI | Automação em lote; conversão headless | Fidelidade de layout variável; sem OCR |
| Recurso | Suporte |
|---|---|
PDF→DOCX direto | Sim |
OCR | Não |
Fontes incorporadas | Parcial |
Layouts complexos | Moderado |
Automação | Sim |
Formulários XFA | Não |
| Recurso | Suporte |
|---|---|
PDF→DOCX direto | Não (codificação manual) |
OCR | Não (é necessário OCR externo) |
Fontes incorporadas | Apenas leitura |
Layouts complexos | Alto controle, manual |
Automação | Excelente |
Formulários XFA | Não |
| Recurso | Suporte |
|---|---|
PDF→DOCX direto | Não |
OCR | Não |
Fontes incorporadas | Não |
Layouts complexos | Bom para tabelas |
Automação | Sim |
Formulários XFA | Não |
| Recurso | Suporte |
|---|---|
PDF→DOCX direto | Sim (via LaTeX) |
OCR | Não |
Fontes incorporadas | Não |
Layouts complexos | Limitado |
Automação | Excelente |
Formulários XFA | Não |
| Recurso | Suporte |
|---|---|
PDF→DOCX direto | Sim |
OCR | Não |
Fontes incorporadas | Parcial |
Layouts complexos | Moderado |
Automação | Excelente |
Formulários XFA | Não |

Converta para formatos editáveis Word/Excel/PowerPoint/Texto/Imagem/HTML/EPUB
Várias funções de edição Criptografia/descriptografia/divisão/fusão/marca d'água etc.
Suporte a OCR extraia textos de PDFs escaneados, imagens e fontes incorporadas
A edição/conversão é rápida Edite/converta rapidamente vários arquivos ao mesmo tempo.
Compatível com Windows 11/10/8/8.1/Vista/7/XP/2000
Converta para formatos editáveis Word/Excel/PowerPoint/Texto/Imagem/HTML/EPUB
Suporte a OCR extraia textos de PDFs escaneados, imagens e fontes incorporadas
Compatível com Windows 11/10/8/8.1/Vista/7/XP/2000
Principais vantagens incluem
Converta para formatos editáveis Word/Excel/PowerPoint/Texto/Imagem/HTML/EPUB
Várias funções de edição Criptografia/descriptografia/divisão/fusão/marca d'água etc.
Suporte a OCR extraia textos de PDFs escaneados, imagens e fontes incorporadas
A edição/conversão é rápida Edite/converta rapidamente vários arquivos ao mesmo tempo.
Compatível com Windows 11/10/8/8.1/Vista/7/XP/2000
Converta para formatos editáveis Word/Excel/PowerPoint/Texto/Imagem/HTML/EPUB
Suporte a OCR extraia textos de PDFs escaneados, imagens e fontes incorporadas
Compatível com Windows 11/10/8/8.1/Vista/7/XP/2000
Passos
pip install pymupdf python-docx watchdog
import fitz # PyMuPDF
from docx import Document
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
import os
class PDFHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith('.pdf'):
self.convert_pdf_to_docx(event.src_path)
def convert_pdf_to_docx(self, pdf_path):
doc = fitz.open(pdf_path)
word_doc = Document()
for page in doc:
text = page.get_text()
word_doc.add_paragraph(text)
output_path = pdf_path.replace('.pdf', '.docx')
word_doc.save(output_path)
print(f"Converted: {output_path}")
if __name__ == "__main__":
path = "watch_folder" # Create this folder
if not os.path.exists(path):
os.makedirs(path)
event_handler = PDFHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
python pdf_to_docx_automate.py
Limitações
- Controle total do código e personalização
- Gratuito para PDFs nativos simples
- Integração fácil em pipelines Python existentes
Cons:
- Sem OCR integrado para documentos digitalizados
- Tabelas complexas e imagens frequentemente ficam desalinhadas
- Requer ferramentas externas para execução agendada
- Necessita muita depuração para diferentes layouts de PDF
| Caso de uso | Ferramenta recomendada |
|---|---|
Teste rápido em 1–2 PDFs simples | Script Python com pdf2docx |
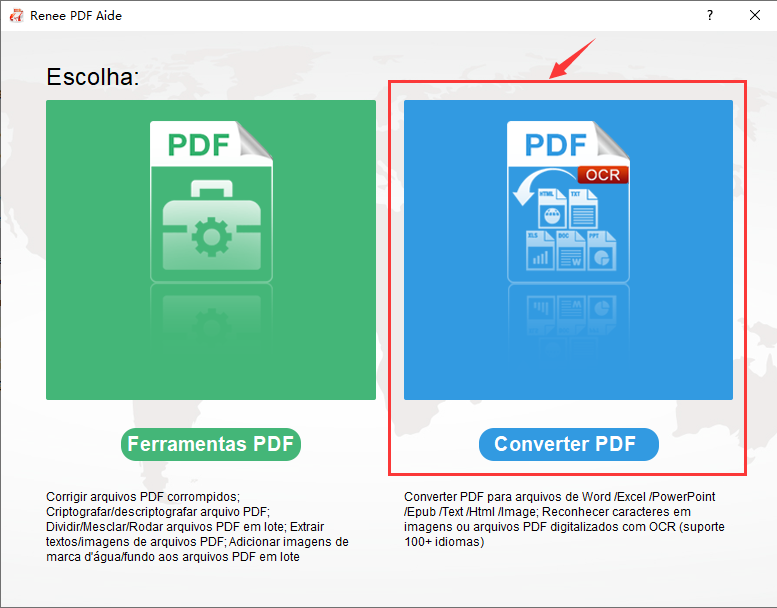
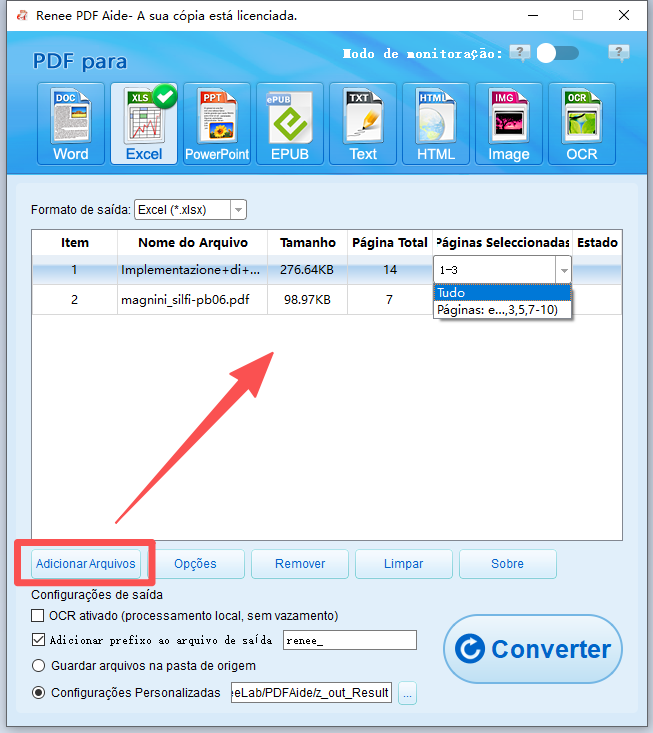
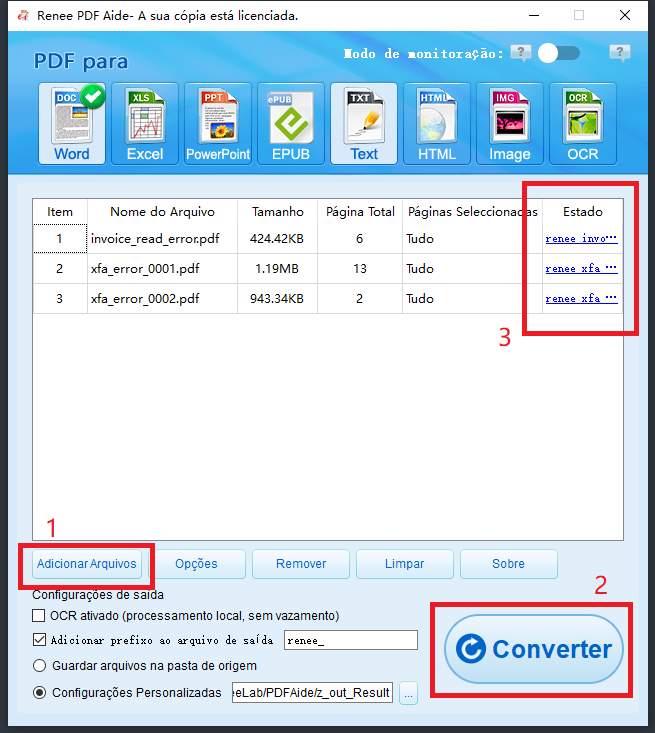
PDFs digitalizados ou layouts complexos | Renee PDF Aide com OCR |
Conversão em lote (50+ arquivos) | Renee PDF Aide (lote + modo de monitoramento) |
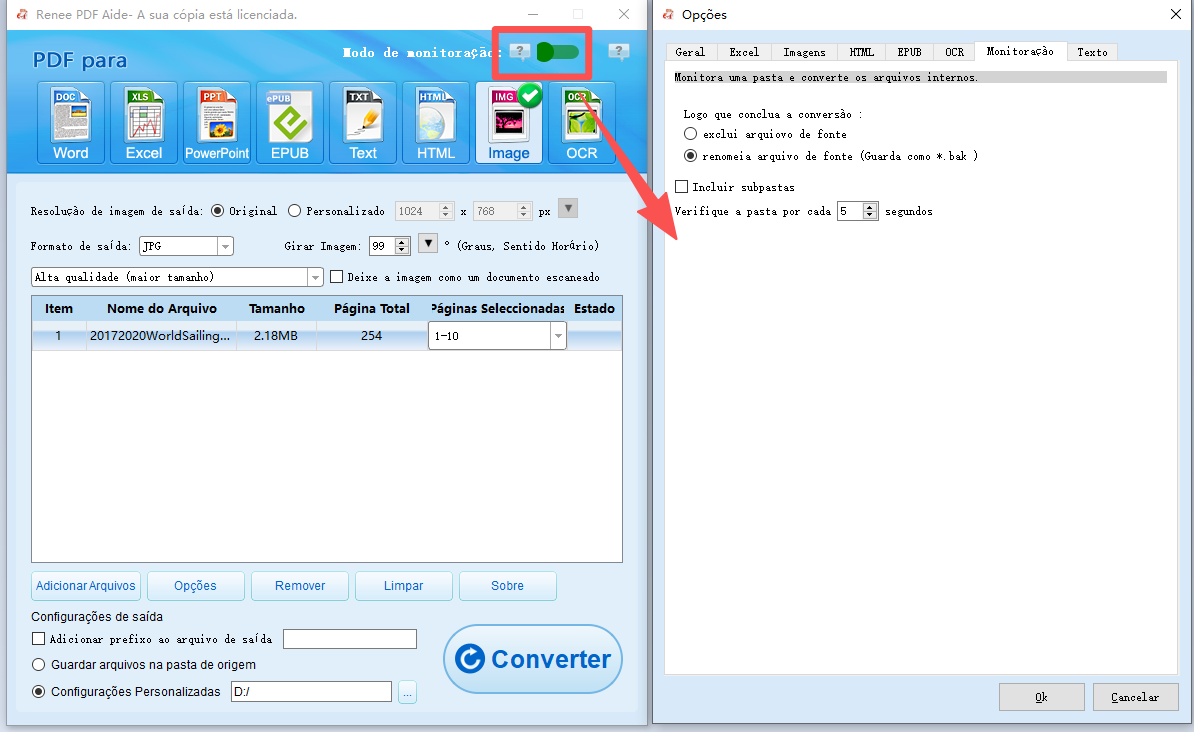
Conversões noturnas agendadas | Modo de monitoramento do Renee PDF Aide |
Controle total do código + PDFs simples | Script personalizado com PyMuPDF + watchdog |
O Renee PDF Aide lida com PDFs digitalizados que scripts Python não conseguem ler?
Por que o pdf2docx perde a formatação das minhas tabelas ou o alinhamento das colunas?
Qual é o tamanho máximo de lote ou limite de páginas no Renee PDF Aide?
Posso converter PDFs protegidos por senha para DOCX com Python ou com o Renee PDF Aide?
O Renee PDF Aide funciona com formulários XFA (PDFs bancários/governamentais)?

Converta para formatos editáveis Word/Excel/PowerPoint/Texto/Imagem/HTML/EPUB
Várias funções de edição Criptografia/descriptografia/divisão/fusão/marca d'água etc.
Suporte a OCR extraia textos de PDFs escaneados, imagens e fontes incorporadas
A edição/conversão é rápida Edite/converta rapidamente vários arquivos ao mesmo tempo.
Compatível com Windows 11/10/8/8.1/Vista/7/XP/2000
Converta para formatos editáveis Word/Excel/PowerPoint/Texto/Imagem/HTML/EPUB
Suporte a OCR extraia textos de PDFs escaneados, imagens e fontes incorporadas
Compatível com Windows 11/10/8/8.1/Vista/7/XP/2000
Link relacionado :
Como Extrair Tabelas de PDFs: As Melhores Ferramentas Grátis e com IA

28-10-2025
Ana : Veja como extrair tabelas de PDFs em 2025 usando ferramentas grátis e IA avançada, ideal para profissionais no...
Como Extrair Texto de PDF Fácil e Rápido: Solução Prática para Iniciantes

03-10-2025
Luísa : Descubra como extrair texto de arquivos PDF de forma fácil e gratuita usando ferramentas online e tecnologia OCR....


Comentários dos usuários
Deixe um comentário