Como Extrair Texto de PDF Fácil e Rápido: Solução Prática para Iniciantes

Resumo
Descubra como extrair texto de arquivos PDF de forma fácil e gratuita usando ferramentas online e tecnologia OCR. Veja dicas práticas para agilizar seus estudos ou trabalho e economize tempo com métodos simples e eficientes!

Sumário


Passos para Copiar e Colar Texto página por página


Copiar texto de PDF resulta em caracteres embaralhados
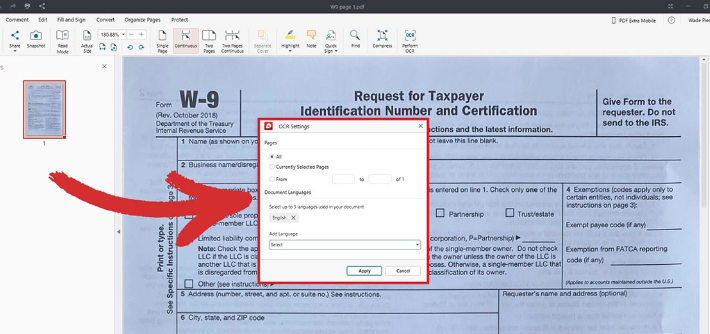
Arquivos PDF digitalizados

Converta para formatos editáveis Word/Excel/PowerPoint/Texto/Imagem/HTML/EPUB
Várias funções de edição Criptografia/descriptografia/divisão/fusão/marca d'água etc.
Suporte a OCR extraia textos de PDFs escaneados, imagens e fontes incorporadas
A edição/conversão é rápida Edite/converta rapidamente vários arquivos ao mesmo tempo.
Compatível com Windows 11/10/8/8.1/Vista/7/XP/2000
Converta para formatos editáveis Word/Excel/PowerPoint/Texto/Imagem/HTML/EPUB
Suporte a OCR extraia textos de PDFs escaneados, imagens e fontes incorporadas
Compatível com Windows 11/10/8/8.1/Vista/7/XP/2000
Como Usar IA para Extração de Texto
Extract all text from this image and do not summarize the text.
Extract all text from this pdf file.

Em muitos casos, os usuários precisam capturar capturas de tela página por página manualmente, o que é demorado e propenso a erros. Para cargas de trabalho maiores ou uso profissional, um software de desktop dedicado continua sendo a escolha mais confiável e eficiente.
📊 Manipulação de PDF: Planos Gratuitos vs. Pagos (Atualização 2025)
| Plataforma | Versão Gratuita | Versão Paga / Premium | Suporte a Conversão de PDF | Formatos de Saída | Melhorias de IA-OCR 2025 |
|---|---|---|---|---|---|
Microsoft Copilot | Envie PDFs de até 50 páginas; divida arquivos grandes. Integra com Edge para OCR rápido. | Microsoft 365: Páginas ilimitadas, extração de tabelas alimentada por IA. | ❌ Sem conversão direta, mas exporta para JSON via API. | Texto simples, JSON | Cognitive Services v3.1: 98% de precisão para documentos digitalizados. |
ChatGPT (OpenAI) | Sem envio direto; cole texto ou captura de tela. | Plus/Team: Envie até 300 páginas; OCR automático para imagens. | ❌ Apenas resume; use plugins para exportar. | Texto simples, listas com marcadores | Integração LlamaParse: Manipula PDFs multilíngues (por exemplo, inglês+hindi). |
Grok (xAI) | Envie ~50 páginas; busca semântica para texto. | Premium: ~200 páginas, processamento em lote. | ❌ Apenas texto simples. | Texto simples | OCR aprimorado para digitalizações de baixa qualidade; focado em privacidade. |
PDFs
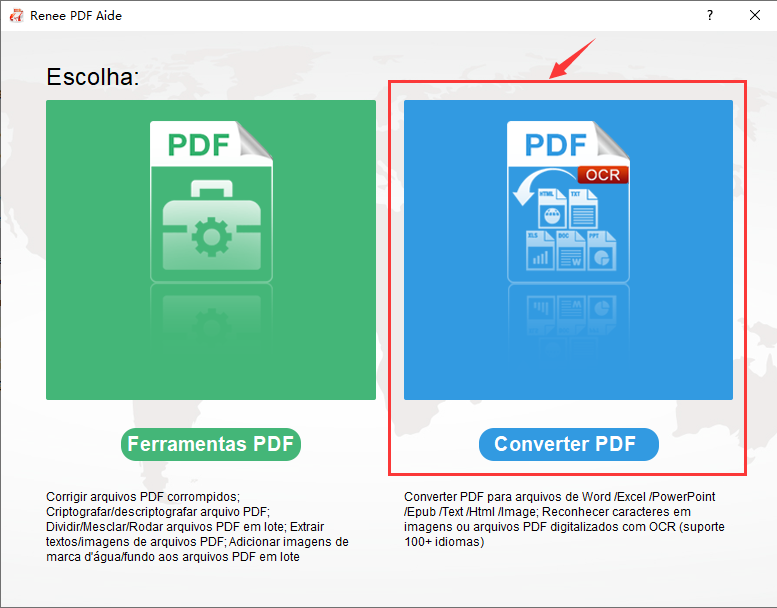
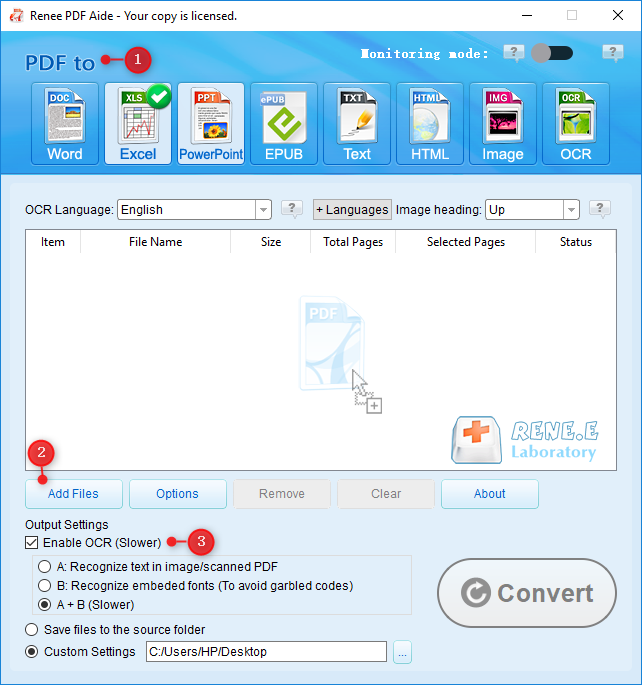
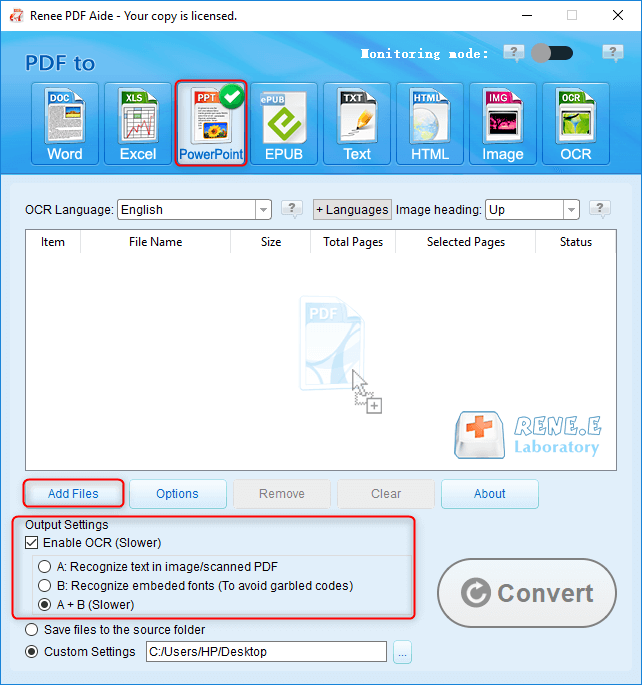
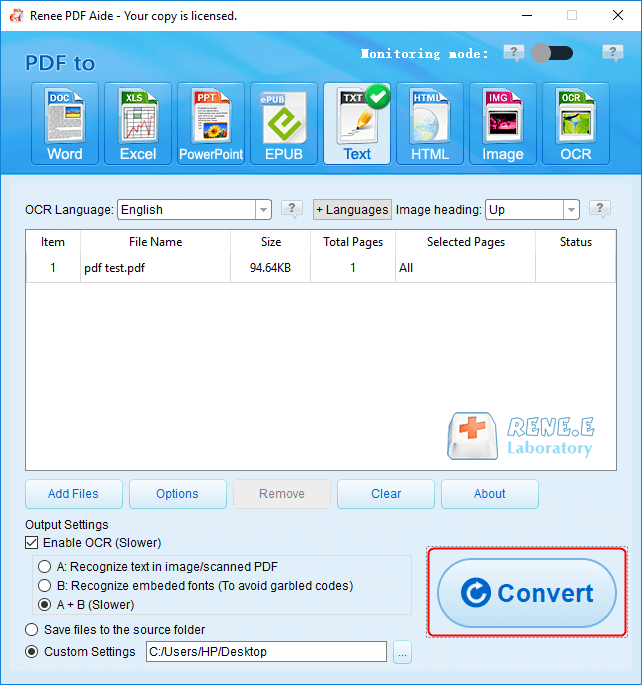
O que é Renee PDF Aide?
Converta para formatos editáveis Word/Excel/PowerPoint/Texto/Imagem/HTML/EPUB
Várias funções de edição Criptografia/descriptografia/divisão/fusão/marca d'água etc.
Suporte a OCR extraia textos de PDFs escaneados, imagens e fontes incorporadas
A edição/conversão é rápida Edite/converta rapidamente vários arquivos ao mesmo tempo.
Compatível com Windows 11/10/8/8.1/Vista/7/XP/2000
Converta para formatos editáveis Word/Excel/PowerPoint/Texto/Imagem/HTML/EPUB
Suporte a OCR extraia textos de PDFs escaneados, imagens e fontes incorporadas
Compatível com Windows 11/10/8/8.1/Vista/7/XP/2000
Extraia Texto para Word
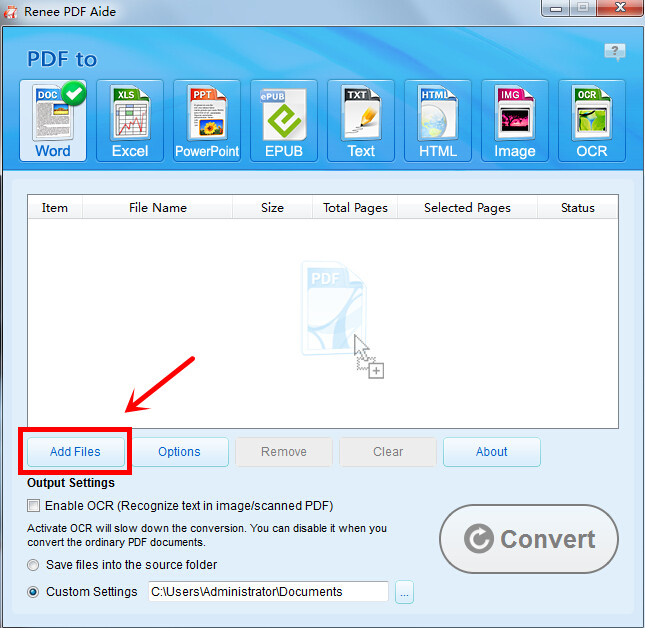
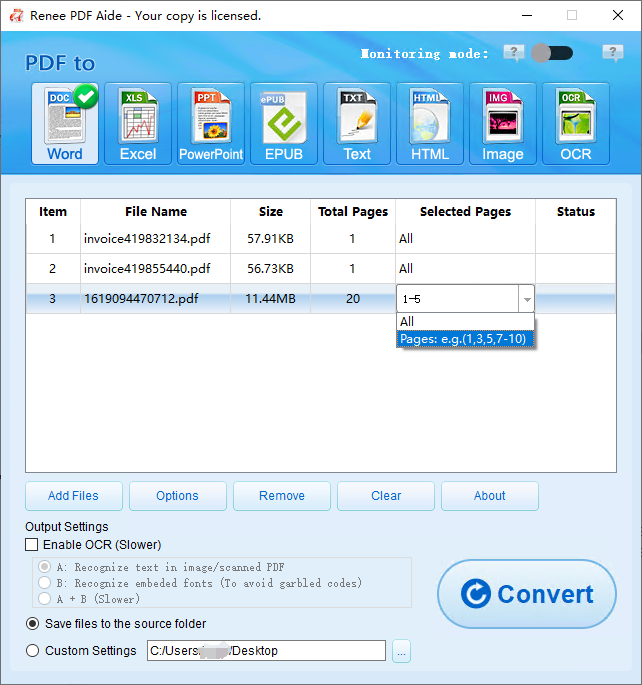

Extraia Texto para Excel
Extraia Texto para PowerPoint
Extraia Texto para TXT

| Ferramenta | Recursos | Limitações |
|---|---|---|
PDF Candy | Conversão gratuita de PDF para TXT, OCR automático para arquivos digitalizados, interface amigável. Ideal para extrair listas de produtos de catálogos. | Limites de tamanho de arquivo (~100MB), anúncios na versão gratuita, mais lento em horários de pico, riscos de privacidade por envios para servidor. |
PDF2Go | Sem necessidade de registro, suporta mobile, conversão rápida para TXT com OCR. Ótimo para notas rápidas de PDFs de reuniões. | Tamanho de arquivo limitado, exposição potencial de dados, perda ocasional de formatação, requer internet. |
Exemplo de Script Python
pip install PyMuPDF tesserocr python-docx Pillow
import os
import fitz # PyMuPDF
import pytesseract
from PIL import Image
from docx import Document
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def extract_text_to_file(pdf_path, output_format="txt", lang="eng"):
try:
doc = fitz.open(pdf_path)
text_output = []
for page_num, page in enumerate(doc, start=1):
text = page.get_text().strip()
if text:
text_output.append(f"--- Page {page_num} ---\n{text}\n")
else:
pix = page.get_pixmap()
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
ocr_text = pytesseract.image_to_string(img, lang=lang)
text_output.append(f"--- Page {page_num} (OCR) ---\n{ocr_text}\n")
doc.close()
output_file = f"{os.path.splitext(pdf_path)[0]}.{output_format}"
full_text = "\n".join(text_output)
if output_format == "txt":
with open(output_file, "w", encoding="utf-8") as f:
f.write(full_text)
elif output_format == "docx":
docx = Document()
docx.add_paragraph(full_text)
docx.save(output_file)
else:
raise ValueError("Unsupported output format. Use 'txt' or 'docx'.")
return output_file
except Exception as e:
print(f"Error processing PDF: {e}")
return None
if __name__ == "__main__":
pdf_file = "sample.pdf"
result = extract_text_to_file(pdf_file, output_format="txt", lang="eng+hin")
if result:
print(f"Text extracted to: {result}")✅ Prós: Gratuito, personalizável
❌Contras: Requer configuração
hin+eng para OCR preciso. Salve como TXT para texto simples ou Word para edição formatada.| Tipo de Usuário | Melhor Método | Prós | Próxima Ação |
|---|---|---|---|
Iniciante | Copiar-Colar ou Ferramentas Online | Simples, sem custo ou habilidades necessárias. | Abra seu PDF no Foxit Reader hoje. |
Profissional | Renee PDF Aide | Conversões rápidas para Word/Excel, offline seguro. | Baixe a versão de teste do site oficial. |
Entusiasta de Tecnologia | Python com OCR | Automatizado, escalável para big data. | Instale dependências e teste o código. |
Usuário Móvel | Assistentes de IA | Funciona em qualquer lugar com internet. | Experimente ChatGPT Plus para envios. |
E se o texto extraído estiver embaralhado ou incompleto?
As ferramentas online são seguras para PDFs sensíveis?
Posso extrair texto de PDFs criptografados?
Como lidar com PDFs grandes (por exemplo, mais de 500 páginas)?
Como extrair texto de PDFs multilíngues?
hin+eng) para extração precisa de PDFs bilíngues.A extração de texto mantém a formatação original do PDF?
Link relacionado :
OCR do Renee PDF Aide Não Funciona? Veja Como Resolver o Erro de AVX

25-08-2025
Ana : Quer descobrir por que o OCR do Renee PDF Aide é tão rápido e preciso? O segredo está...
PDF Travado? Veja Como Transformar em Planilha do Google Fácil e Rápido

10-06-2025
Sónia : Aprenda como converter arquivos PDF em planilhas Excel de forma rápida e gratuita usando o Google Sheets. Veja...
Como Converter PDF em Excel: Solução Prática para Extrair Texto Fácil

10-06-2025
Pedro : Aprenda como extrair textos de PDFs para o Excel de forma fácil e eficiente. Veja dicas, métodos gratuitos...
Como Extrair Texto na Imagem: Guia Prático de OCR
28-09-2024
Luísa : Aprenda a extrair texto de imagens JPG/BMP de forma simples usando a tecnologia OCR. Recomendamos software de ponta...


Comentários dos usuários
Deixe um comentário